Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM
 Skip to content
Skip to contentAddress
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM

A medida que estos LLM se hagan más grandes y complejos, sus capacidades mejorarán. Sabemos que ChatGPT-4 tiene alrededor de 1 billón de parámetros (aunque OpenAI no lo confirma), frente a los 175 mil millones en ChatGPT 3.5
Los grandes modelos de lenguaje, como los chatbots de IA, parecen estar en todas partes. Si los comprende mejor, podrá utilizarlos mejor.
CHATBOTS IMPULSADOS POR IA COMO: Como ChatGPT y Google Bard ciertamente están pasando por su momento: la próxima generación de herramientas de software conversacional promete hacer de todo, desde hacerse cargo de nuestras búsquedas en la web hasta producir un suministro interminable de literatura creativa y recordar todo el conocimiento del mundo para que nosotros no tengamos que hacerlo.
ChatGPT, Google Bard y otros bots como ellos son ejemplos de grandes modelos de lenguaje , o LLM, y vale la pena profundizar en cómo funcionan. Significa que podrá utilizarlos mejor y apreciar mejor en qué son buenos (y en qué no se les debe confiar).
Al igual que muchos sistemas de inteligencia artificial, como los diseñados para reconocer su voz o generar imágenes de gatos, los LLM están entrenados con enormes cantidades de datos. Las empresas detrás de ellos han sido bastante cautelosas a la hora de revelar de dónde provienen exactamente esos datos, pero hay ciertas pistas que podemos analizar.
Por ejemplo, el artículo de investigación que presenta el modelo LaMDA (Modelo de lenguaje para aplicaciones de diálogo), en el que se basa Bard, menciona Wikipedia, “foros públicos” y “documentos de código de sitios relacionados con la programación, como sitios de preguntas y respuestas, tutoriales, etc.” Mientras tanto, Reddit quiere comenzar a cobrar por el acceso a sus 18 años de conversaciones de texto, y StackOverflow acaba de anunciar planes para comenzar a cobrar también. La implicación aquí es que los LLM han estado haciendo un uso extensivo de ambos sitios hasta este momento como fuentes, completamente gratis y a costa de las personas que construyeron y utilizaron esos recursos. Está claro que los LLM han extraído y analizado gran parte de lo que está disponible públicamente en la web.
Todos estos datos de texto, vengan de donde vengan, se procesan a través de una red neuronal, un tipo de motor de IA de uso común compuesto por múltiples nodos y capas. Estas redes ajustan continuamente la forma en que interpretan y dan sentido a los datos en función de una serie de factores, incluidos los resultados de pruebas y errores previos. La mayoría de los LLM utilizan una arquitectura de red neuronal específica llamada transformador , que tiene algunos trucos particularmente adecuados para el procesamiento del lenguaje. (Ese GPT después de Chat significa Transformador preentrenado generativo).
Específicamente, un transformador puede leer grandes cantidades de texto, detectar patrones en cómo las palabras y frases se relacionan entre sí y luego hacer predicciones sobre qué palabras deberían aparecer a continuación. Es posible que haya escuchado que se comparan los LLM con motores de autocorrección sobrealimentados, y eso en realidad no está muy lejos de la realidad: ChatGPT y Bard realmente no “saben” nada, pero son muy buenos para descubrir qué palabra sigue a otra, cuál comienza a parece pensamiento y creatividad reales cuando llega a una etapa lo suficientemente avanzada.
Una de las innovaciones clave de estos transformadores es el mecanismo de autoatención. Es difícil de explicar en un párrafo, pero en esencia significa que las palabras de una oración no se consideran de forma aislada, sino también en relación entre sí en una variedad de formas sofisticadas. Permite un mayor nivel de comprensión del que sería posible de otro modo.
Hay cierta aleatoriedad y variación integradas en el código, por lo que no obtendrás siempre la misma respuesta de un chatbot transformador. Esta idea de autocorrección también explica cómo pueden aparecer errores. En un nivel fundamental, ChatGPT y Google Bard no saben qué es exacto y qué no. Buscan respuestas que parezcan plausibles y naturales, y que coincidan con los datos con los que han sido entrenados.
Entonces, por ejemplo, es posible que un bot no siempre elija la palabra más probable que viene a continuación, sino la segunda o tercera más probable. Sin embargo, si se lleva esto demasiado lejos, las oraciones dejarán de tener sentido, razón por la cual los LLM están en un estado constante de autoanálisis y autocorrección. Por supuesto, parte de una respuesta depende de la entrada, por lo que puedes pedirles a estos chatbots que simplifiquen sus respuestas o las hagan más complejas.
También puede notar que el texto generado es bastante genérico o cliché, tal vez lo que se espera de un chatbot que intenta sintetizar respuestas de repositorios gigantes de texto existente. De alguna manera, estos robots están produciendo oraciones en serie de la misma manera que una hoja de cálculo intenta encontrar el promedio de un grupo de números, dejándote con un resultado completamente anodino y mediocre. Haga que ChatGPT hable como un vaquero, por ejemplo, y será el vaquero más sencillo y obvio posible.
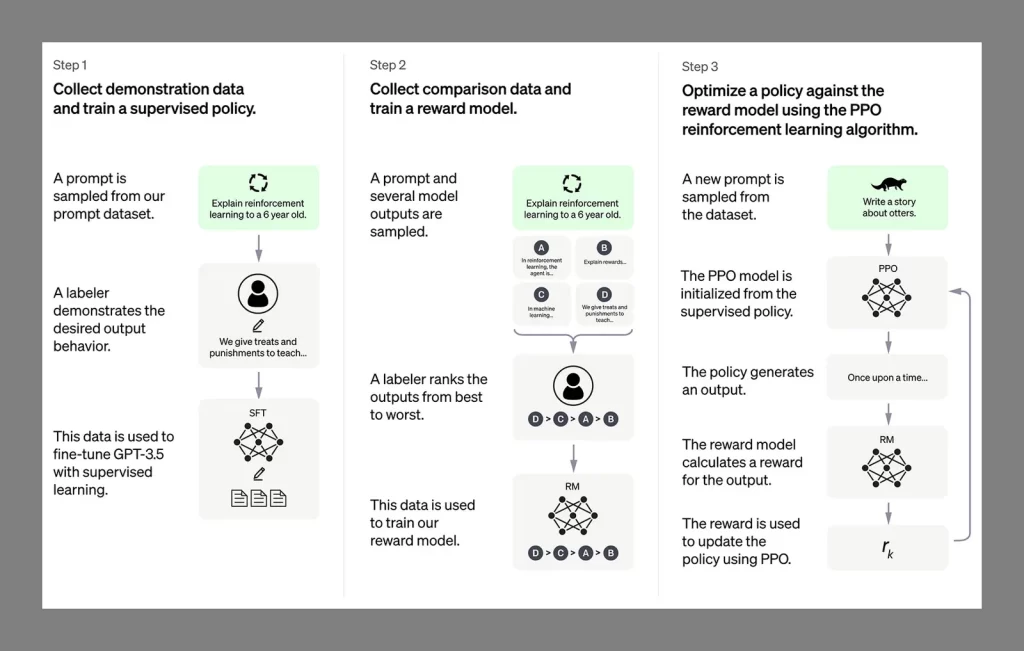
Los seres humanos también están involucrados en todo esto (por lo que no somos del todo redundantes todavía): tanto los supervisores capacitados como los usuarios finales ayudan a capacitar a los LLM señalando errores, clasificando las respuestas según lo buenas que sean y dando a la IA una alta puntuación. -Resultados de calidad a los que aspirar. Técnicamente, se conoce como “aprendizaje por refuerzo sobre retroalimentación humana” (RLHF). Luego, los LLM refinan aún más sus redes neuronales internas para obtener mejores resultados la próxima vez. (Estos son todavía relativamente primeros días para la tecnología a este nivel, pero ya hemos visto numerosos avisos de actualizaciones y mejoras por parte de los desarrolladores).
A medida que estos LLM se hagan más grandes y complejos, sus capacidades mejorarán. Sabemos que ChatGPT-4 tiene alrededor de 1 billón de parámetros (aunque OpenAI no lo confirma), frente a los 175 mil millones en ChatGPT 3.5; un parámetro es una relación matemática que vincula palabras a través de números y algoritmos. Se trata de un gran salto en términos de comprender las relaciones entre palabras y saber cómo unirlas para crear una respuesta.
Almacenes de datos locales versus almacenes de datos en la nube: pros y contras
 Optimized by Seraphinite Accelerator
Optimized by Seraphinite Accelerator